Key Highlights –
- Microsoft has added two multi-model features to Microsoft 365 Copilot Researcher: Critique, a dual-model draft-and-review system, and Council, which runs Anthropic and OpenAI models simultaneously and compares their outputs through a third judge model
- Critique outperforms Perplexity’s Claude Opus 4.6 by 13.88% on the DRACO research benchmark, according to Microsoft’s own evaluation, which is the first time Microsoft has published a direct comparative benchmark against a named competitor in this context
- Both features are currently available through the Microsoft 365 Copilot Frontier program, targeted at enterprise users; broader rollout timing has not been confirmed
Microsoft announced Critique and Council today via Satya Nadella’s X account, with supporting documentation published simultaneously on the Microsoft Tech Community blog. Both features sit inside Microsoft 365 Copilot Researcher, the tool aimed at enterprise professionals who need structured, sourced research outputs rather than conversational responses.
As you may know, Copilot has historically operated on a single model at a time which was typically OpenAI’s GPT series, with Microsoft progressively integrating other vendors. Critique and Council represent a structural shift in how Copilot approaches research tasks, moving from a single model generating a response to multiple models working in sequence or in parallel.
How Critique Works
Critique is built on a two-model pipeline. The first model handles the research itself – planning the approach, sourcing relevant material, and synthesising a draft. The second model then reviews that draft, specifically checking for source reliability, completeness, and whether claims are grounded in evidence rather than inference.
The architecture is designed to catch the category of errors that single-model research consistently produces: confident-sounding claims that are either unsupported or draw from low-quality sources. Whether a two-model check eliminates that problem in practice is an open question, but the DRACO benchmark results which is a 13.88% improvement over Perplexity’s Claude Opus 4.6 and gives Microsoft a concrete, named data point to stand behind. That specificity is unusual. Most AI product announcements cite internal benchmarks without naming the competitor being surpassed.
How Council Works
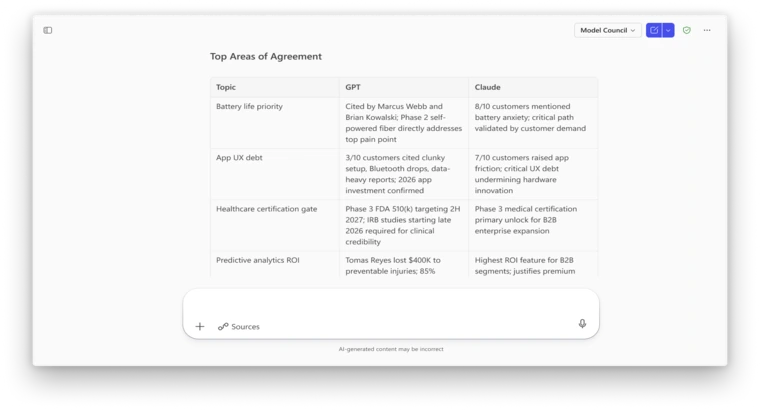
Council takes a different approach. Rather than models working in sequence, Council runs both Anthropic and OpenAI models on the same research prompt simultaneously. A third model then acts as a judge, reviewing both outputs and generating a summary that flags where they agree, where they diverge, and what each adds uniquely.
For perspective, this is a meaningful product decision beyond technical architecture. Microsoft is now actively positioning Claude and GPT as complementary tools within the same enterprise workflow rather than competing alternatives. The practical implication for users: they can, for the first time, see where two leading AI models produce different conclusions on the same research brief, and make an informed call on which to use.
What It Means for Enterprise AI
The broader signal here is that Microsoft is moving toward a multi-vendor AI stack at the product layer, not just the infrastructure layer. Building Council into Copilot acknowledges that no single model is definitively better across all research tasks, and that showing users the difference is more valuable than hiding it behind a single interface.
The risk is complexity. Enterprise users who adopted Copilot for simplicity may find a side-by-side model comparison output harder to act on than a single clean answer. Whether Frontier program participants find Council’s judge-model summaries genuinely useful, or even just interesting, will determine how far this feature travels beyond the early access cohort.
Wrapping Up
Critique and Council are not incremental feature updates. They represent a change in how Microsoft thinks Copilot should operate less as a single AI assistant and more as a structured research process with built-in verification. The question the Frontier program will answer is whether enterprise users want their AI to show its working, or whether they just want the answer.


